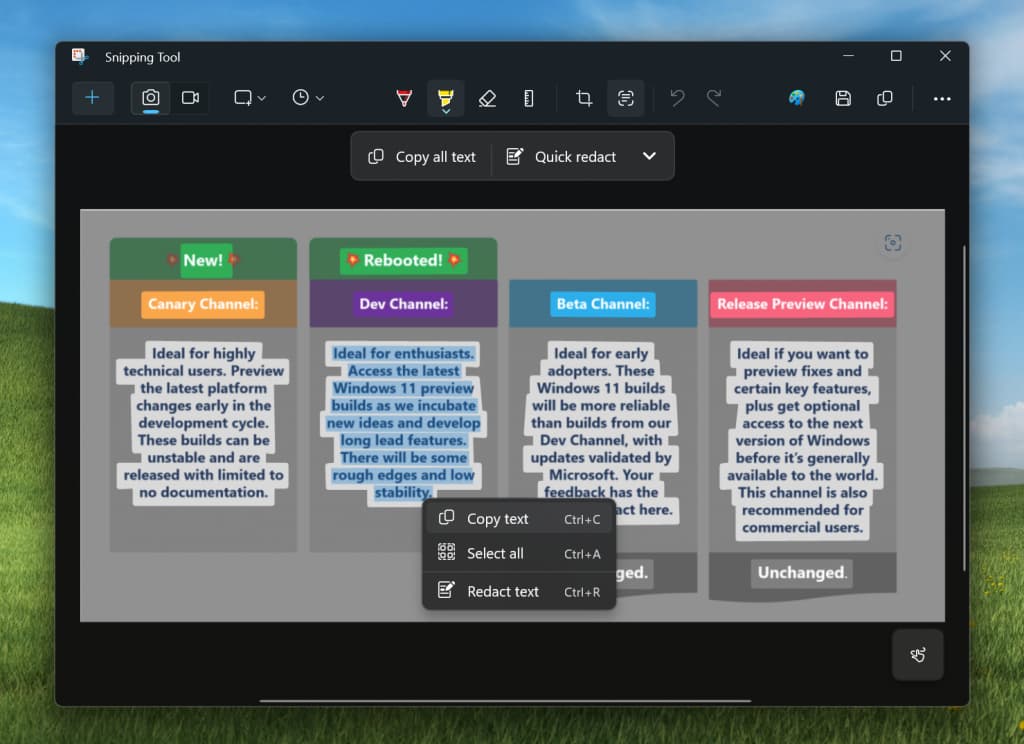
With this update to Snipping Tool (version 11.2308.33.0), we are introducing Text Actions, which detects text in your captured screenshots, making it easy to copy text from any image to share with others or paste in another app. To get started, click the Text Actions button in the toolbar to show selectable text before selecting and copying text with your mouse. You can also click the Copy all text button in the toolbar or use Ctrl + A and Ctrl + C to select and copy all text using your keyboard.
Does a plugin for krita, digikam or gwenview exist to provide such functionality? I’ve not been able to locate anything, despite i(Pad)OS and now Windows 11’s stock applications supporting it.
I’ve not been able to get 🐟 How to use Copyfish Free OCR Software for Chrome and Firefox working, which is partially why I ask, but I also wouldn’t particularly want to download a dedicated GTK application for it, so a plugin for the great KDE image manipulators would be ideal (if one exists).
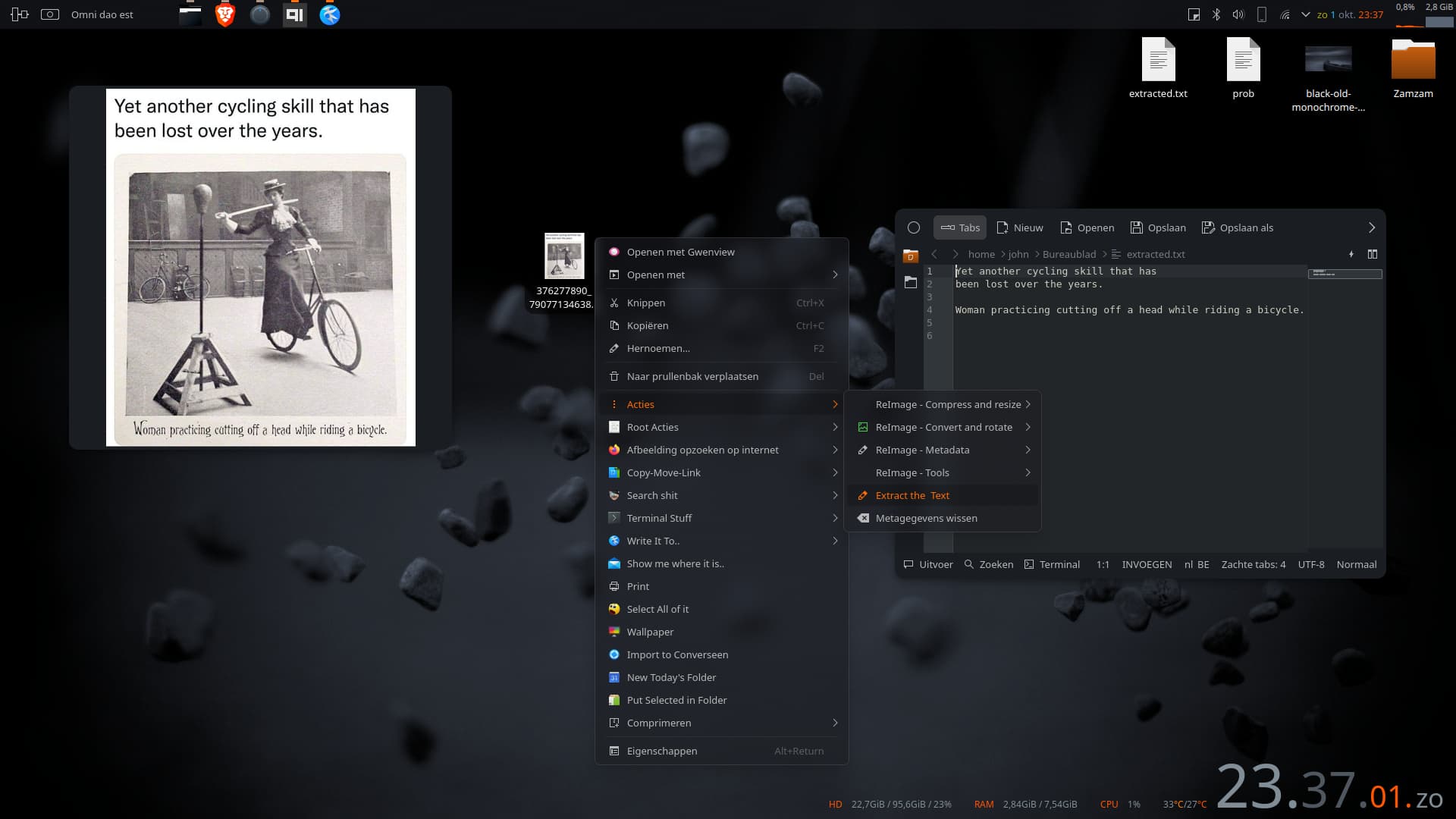
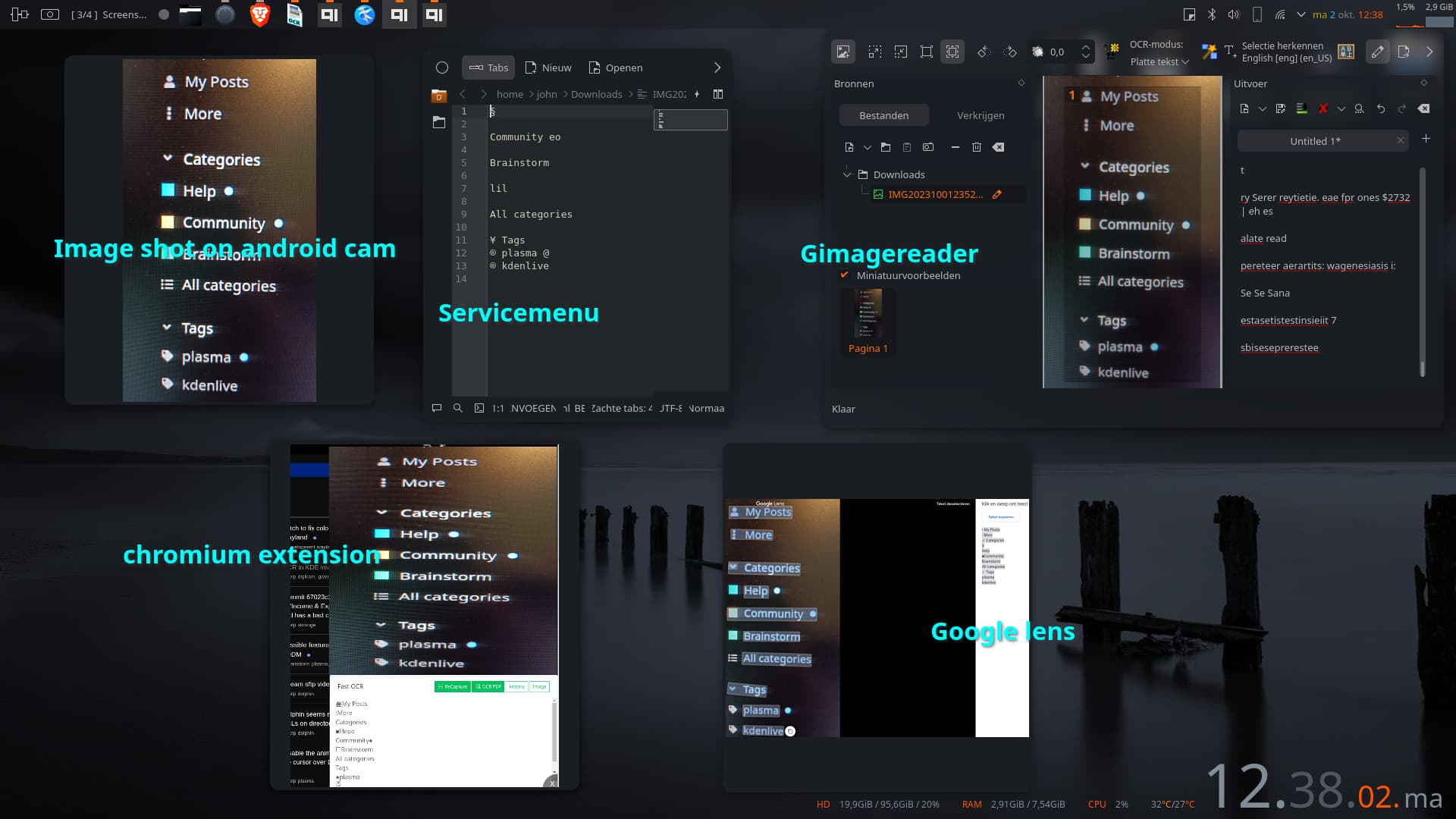
Doesn’t exist…yet. Not that I know of. I sometimes need the functionality and made a little servicemenu for it, using tesseract-ocr. It’s made for one file but I guess you could write a bash script to extract on several files at once and use the original image’s filename for the extracted texts. It’s far from perfect and sometimes the text ( dunno why exactly) can’t be defined. But in most cases and for my needs, it works. Guess for now there’s no real tool available.
On a sidenote. OCR extensions are available in chromium based browsers and probably in firefox as well. For example: OCR image reader Of course, if you want to scan local files you need to allow it with some.
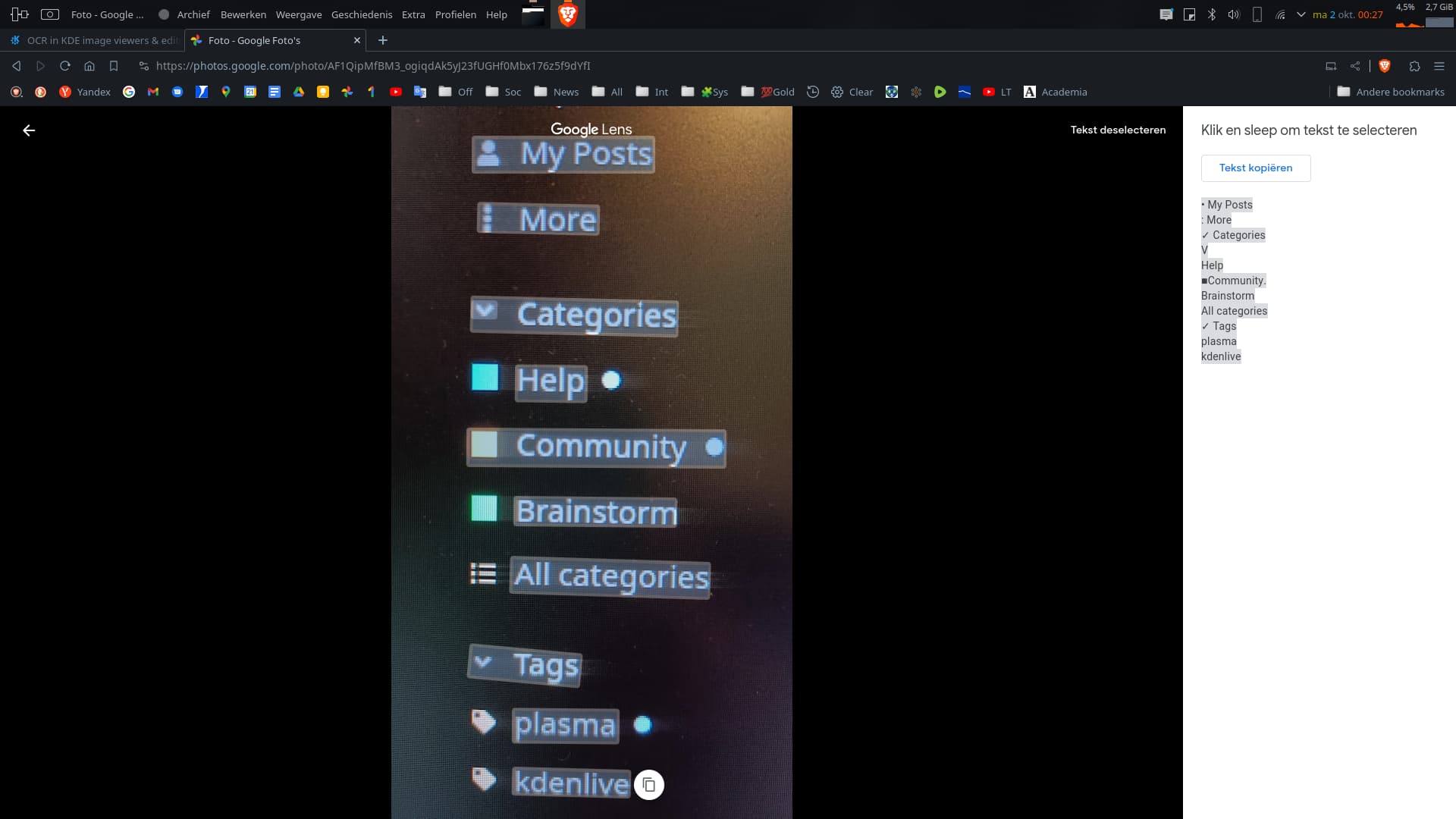
Just tried it out on a png image, reads n extracts to clipboard no problems, works 100%.
Very useful instead trying to type out text from image.
Thank You @chartmann
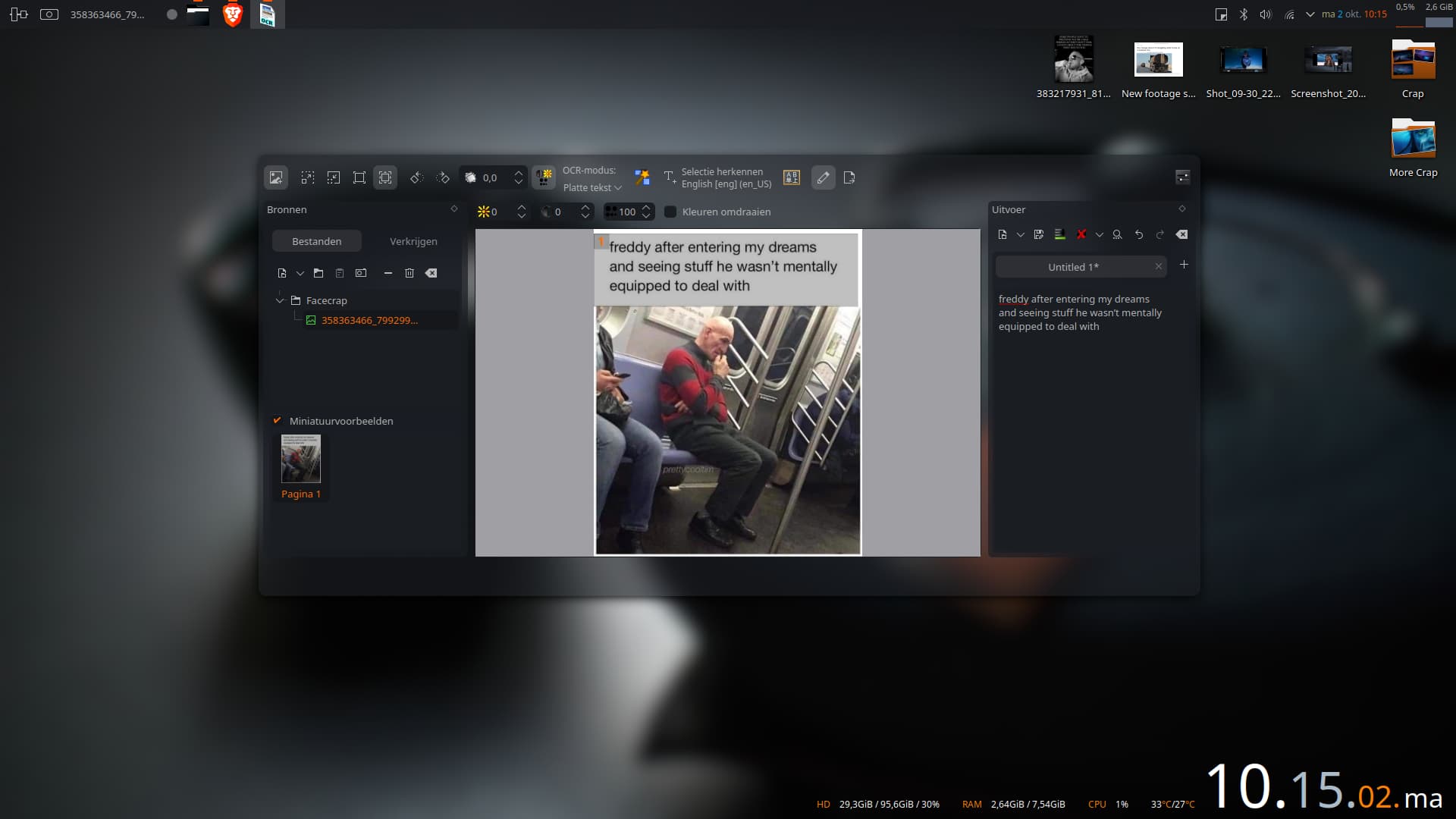
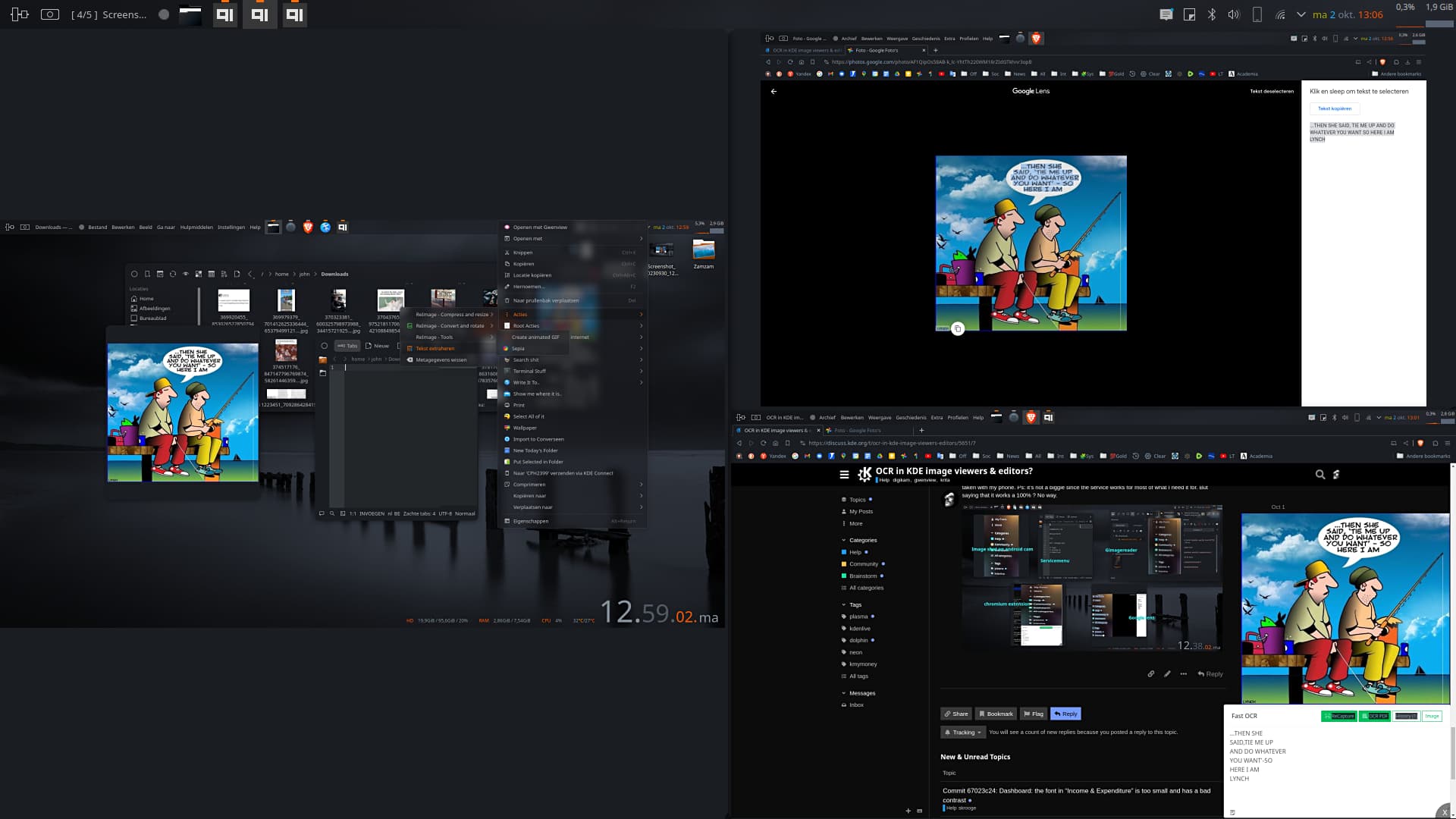
It doesn’t work 100%. I tried a bunch of commands and no matter what, certain texts are NOT recognized ( as I mentioned before). I have no idea why, but certain text WILL get extracted using stuff like gimagereader ( allbeit sometimes with weird syntax) and even better ( although I don’t like it) in certain browser extensions. Windows, Google and Apple probably use a “bit” more to get this to work on practically any image file. Like I said, from time to time I use the functionality but realized there is no such tool ( for now and unless I overlooked it) available in Linux. Here’s an example of a random picture taken with my phone. Ps: it’s not a biggie since the service works for most of what I need it for. But saying that it works a 100% ? No way.
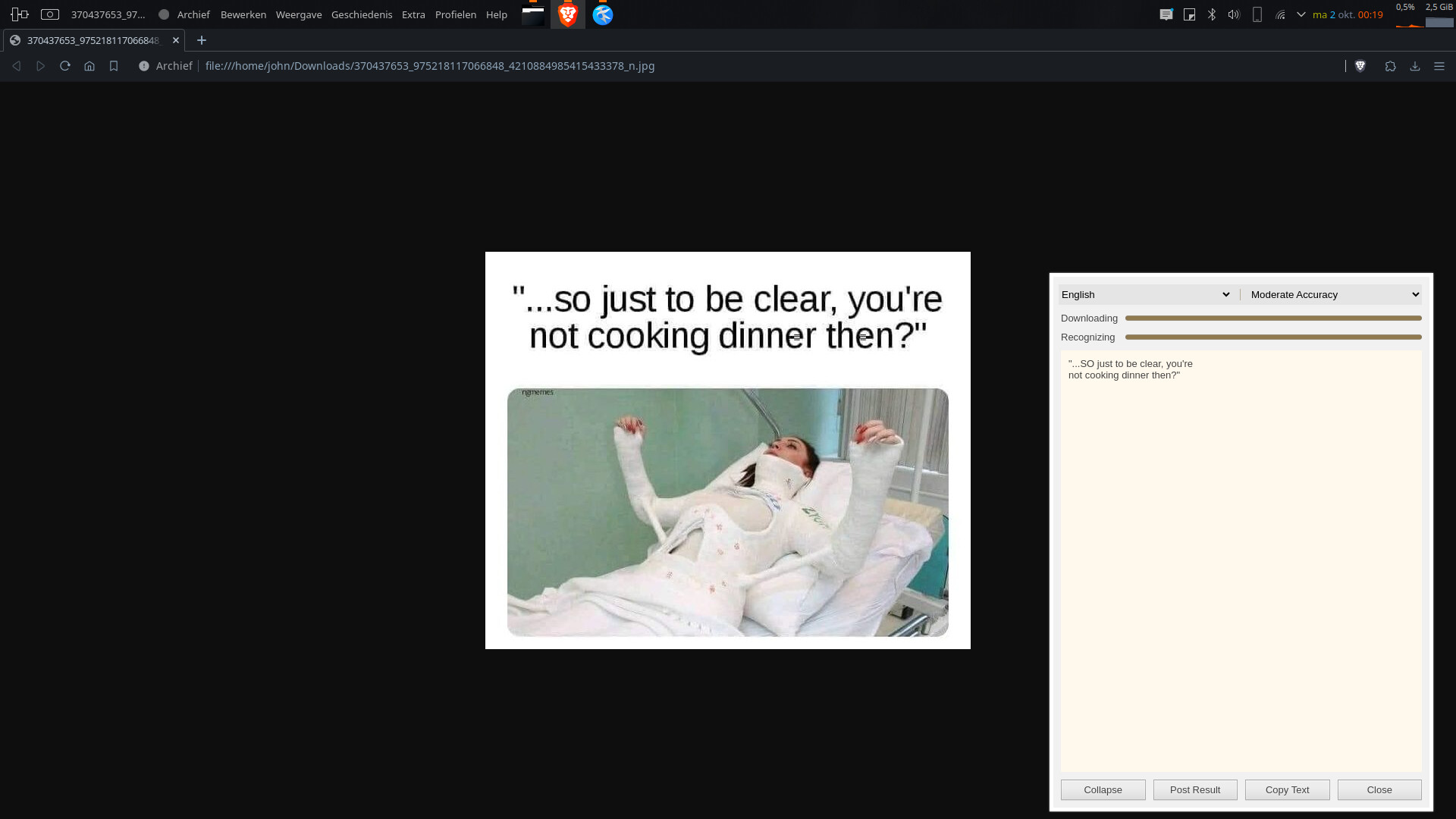
That was the reason I mentioned CopyFish - it’s what I use in all my browsers, because it’s utterly cross-platform and FOSS. However, its Linux integration doesn’t appear to work very well for me, and I’m not even certain that its Linux support is necessarily anything more than a library, rather than the GUI I’d like it to be.
I have no idea man. If I had to put my money on it, I’d say they’ve been using soft AI for a while now. In either case ( I can’t vouch for apple) the Lens thing just about nails it everytime. You know, the usual tryouts, a menu in a resto, roadsigns…that kind of stuff. If I try to extract it on my rig, it’s a hit or miss. Dunno, some light influence, shadows…I really dunno. In either case, the tesseract works for most of what I really need it for. If it fails I upload my stuff and run Geugle over it.
When I wrote that it works 100% it does on images with plain text
took it for a test-out different text this morning and found that anything within a speech bubble has problems and any text similar to handwritten the corners of the speech bubbles (the oval line and/or small blocks of colour throw a spanner in gimagereader) ,
since I will using it for capturing plain text on (of old scans) images pages for me it’s 100% win.
Thank You @chartmann
This is very cool! I took your code, modified it a little, and also had to find out where to save it…
[Desktop Entry]
Type=Service
MimeType=image/*;
Icon=document-edit-sign
Actions=ExtractText;
[Desktop Action ExtractText]
Name=Extract the Text
Icon=document-edit-sign
Exec=tesseract %f %f
The most notable change is the Exec line changed to tesseract %f %f so the output file name is much clearer and re-running this won’t overwrite the singular extracted.txt file.
This needs to be saved as ocr.desktop in $USER/.local/share/kio/servicemenus/ and not in the deprecated location %USER/.local/share/kservices5/ServiceMenus/. It needs to be chmod’ed to be executable as per Creating Dolphin Service Menus | Developer
I didn’t code anything, it’s just a servicemenu. A better one has been posted here and I don’t see why this just HAS to be in kio. But, if it works for you…
since June or so, a fresh install through dolphin context menu settings goes into ~/.local/share/kio/servicemenus/. this seems to be true for updates as well. at least for me, dolphin still uses older ones from ~/.local/share/kservices5/ServiceMenus/ first and ignores the ne one in kio.
[Desktop Entry]
Type=Service
Name=Extract Text (tesseract)
MimeType=image/*;
X-KDE-ServiceTypes=KonqPopupMenu/Plugin
Icon=text-flow-into-frame
Actions=ReadIt
TryExec=tesseract
[Desktop Action ReadIt]
Name=Extract text
Name[de]=Text extrahieren
Name[fr]=Extraire du texte
Name[it]=Estrarre il testo
Name[ar]=استخراج النص
Name[is]=Draga út texta
Name[ch]=提取文本
Name[da]=Udtrække tekst
Name[et]=Udtrække tekst
Name[fi]=Poimia tekstiä
Name[ka]=Ტექსტის ამოღება
Name[el]=Εξαγωγή κειμένου
Name[he]=לחלץ טקסט
Name[id]=Ekstrak teks
Name[ga]=Sliocht téacs
Name[is]=Draga út texta
Name[jp]=テキストを抽出する
Name[ko]=텍스트 추출
Name[lv]=Izvilkt tekstu
Name[lt]=Ištraukite tekstą
Name[mi]=Tango kupu
Name[nl]=Tekst extraheren
Name[no]=Trekke ut tekst
Name[fa]=Trekke ut tekst
Name[pl]=Wyodrębnij tekst
Name[pt]=Extrair texto
Name[sv]=Extrahera text
Name[sk]=Extrahovať text
Name[es]=Extraer texto
Name[th]=แยกข้อความ
Name[cs]=Extrahovat text
Name[uk]=Витягти текст
# Icon=application-text # =
# Icon=artistictext-tool # a # no display
# Icon=edit-select-text # AI # displays arrow up left !?
# Icon=dialog-text-and-font # T # no display
# Icon=text-convert-to-regular # Tt
Icon=text-flow-into-frame
# this extremly simple approch to get the first languge used works ..
# e.g. for italian, german or english, but not for spanish (es!=spa) :(
# it also will brutaly overwrite existing files
Exec=bash -c 'LO="" ; FL="$(tesseract --list-langs | grep ${LANG:0:2})" ; IN="%u" ; OB="${IN%.*}" ; [[ -n "$FL" ]] && LO="-l $FL" ; tesseract ${LO} "${IN}" "${OB}"'
ls ~/.local/share/kservices5/ServiceMenus/
ls: cannot access '/home/RokeJulianLockhart/.local/share/kservices5/ServiceMenus/': No such file or directory